The increasing ubiquity of huge databases, coupled with rapid advances in technologies for storage and analysis of data, has suggested to some observers that twenty-first-century science has entered a new era. At the same time, however, scholars have begun to stress important historical continuities in data practices and epistemologies that stretch back over several hundred years. The new working group led by Elena Aronova, Christine von Oertzen, and David Sepkoski aims to collectively present the first genuinely broad-scale history of practices, epistemologies, material culture, and political consequences of data across scientific disciplines, while adding much needed comparative dimensions and historical depth to the on-going discussion of the revolutionary potential of data-driven modes of knowledge production. The following case studies represent three main areas addressed by the working group.
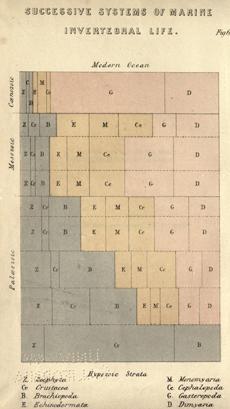
Fig. 2: Frontispiece, representing “the relative proportions of the several classes in successive geological periods.” John Phillips, Life on the Earth; Its Origin and Succession (1860).
How have data and data practices migrated from collection to paper-based then to mechanical and finally to computer-based information technologies? David Sepkoski’s project on “The Database before the Computer” is a comparative analysis of nineteenth- and twentieth-century data approaches in paleontology and zoology. Using examples of large-scale quantitative data collection and analysis of both paper-based taxonomic compendia and eventual digital databases, he shows that practitioners in these fields were engaged in databasing long before computers arrived on the scene. However, he also attends to the ways that changes in the technology and material culture of data between the nineteenth and later twentieth centuries affected data practices and epistemologies, demonstrating that each era faced particular challenges for coping with “data friction,” and new technologies and materialities of data had consequences for the professional division of labor in the taxonomic sciences.

Fig. 3: U.S. Census Bureau machines and operators, 1908. Library of Congress Prints and Photographs Division Washington, D.C.
How did labor and technologies of data production change over time? Christine von Oertzen’s contribution on the “Mechanization of Census Statistics in Europe, 1890-1930” examines the social and political ramifications of the transition from manual to machine data processing across Europe between 1890 and 1930, first and foremost in census taking, but also in industry and warfare. When the word spread among European statisticians about the new American method of electronic tabulating in 1890, the machines appealed much more readily to some societies than others. Von Oertzen focuses on why machine readability found strong advocates in governments in Austria and Russia, whereas British as well as German census statisticians proved quite reluctant to introduce machines to the process of compiling census data. In the German Empire, the unprecedented challenges brought about by the First World War prompted an about-face toward big data machinery. The project will show on what terms the world’s first total war accelerated the adoption of tabulating machines in Central Europe.
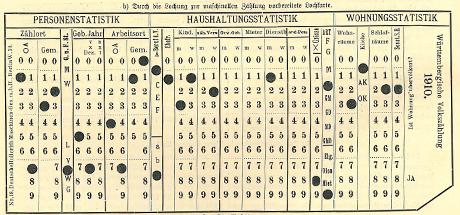
Fig. 4: First punch card used in a German census, 1910. From: Hermann Julius Losch, Die Volkszählung vom 1. Dezember 1910 (1911), p. 184.

Fig. 5: All-sky camera designed during the IGY to photograph active aurora bands. From: Robert H. Eather, Majestic Lights. The Aurora in Science, History, and the Arts, Washington (1980), p. 176.
Where does the power of Big Data come from? Elena Aronova’s project “Do (Big) Data Have Politics? Cold War and the Political Economy of Data Exchange” explores how Big Data acquired renewed legitimacy during the Cold War era, as part of Big Science. Big Science as a notion was coined in early 1960s to describe the mode of organization of science originated in the Second World War and exemplified by such operations as the Manhattan project, space stations, early computers, and particle accelerators: accounts of big machines, big money, and big publicity that did not include big data. Against this background, Aronova’s contribution draws on the history of the World Data Centers, organized to serve the International Geophysical Year (1957–1958), to show how the practices and technologies of the World Data Centers were intimately intertwined with the political economy of data exchange, and as such crucial for the development of contemporary databases in the geophysical sciences.
As these examples show, the precise relationship between technologies, practices, materialities, and epistemologies of data is complex. While technologies have changed—from paper-based to mechanical to digital devices—database practices were more continuous than the technologies and tools used to organize, analyze and represent data. Computer technologies have accelerated and amplified features of data-driven science already present or latent in earlier material cultures of data. The working group aims to present a nuanced genealogy of these features of data-driven science that recognizes both underlying continuities, as well as genuine ruptures. Only by considering these continuities and ruptures can we critically expand the on-going discussion of the revolutionary potential of data-intensive modes of knowledge production.