The epistemic web requires us to rethink fundamental concepts of how to encode and contextualize data in a standardized way. The focus of this project is on making the description of data available for both human- and machine-based interpretation, on the grounds that the two can operate complementarily, without one replacing the other. Here the key aspect of data modeling is to be as precise as possible; this also includes documenting the limits of these methods. An overarching conceptual framework is needed to enable the process of working with sources, the description of and commentary on sources, and the publication of research results.
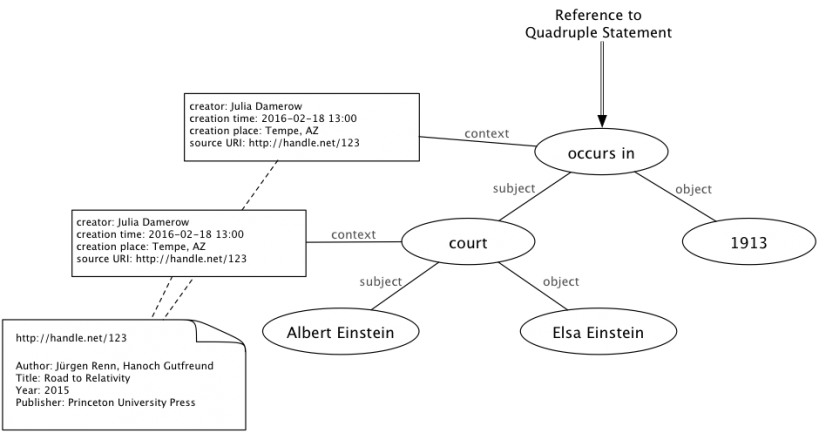
Quadruple Statement.
The framework that is currently developed in cooperation with the Department and the Digital Innovation Group at Arizona State University (led by Manfred Laubichler and Julia Damerow) allows for a description of the interaction of people and institutions based on project-specific interests and also shows the connection to other datasets collected in different contexts. This can occur on the very general level of the pure information of people’s interaction, up to a close description of how this happened. An ontology is therefore required that enables access to the general level of “interaction” up to a very specific form of interaction that is only of interest to the specialist. Starting with an ontology-based approach allows for the classification of objects in a non-exclusive way but still ensures this object is retrievable in a different context. For example, an art historian might classify a picture of the sphere as an artistic object, but a historian of science will classify the same object as scientific. Identifying the existence of this object in different databases is only possible if one can agree on at least one conceptual level. In the worst case, this involves going through all “things,” but—in principle at least—this is quite feasible without relying on any kind of data integration process.